Windowsのファイル検索のコツとその仕組み
注:この記事ではWindows7の画面を使用してますが、Windows10でも同じことができます。
Windowsではファイルの検索は、
フォルダの右上部分にある小さな検索ボックスから検索できます。
しかし、いざ検索してみると
「検索に引っかからない」
「検索が遅い」
「なぜか関係ないものまで検索される」
といった事に悩まされた人も多いのではないのでしょうか?
Windowsでファイルを検索するテクニック
ここでは、Windows7のファイル検索のシステムの仕組みについて紹介します。
また検索のコツを紹介したいと思います。
長くなるので先に結論だけ言います。
まず検索ボックスに入力する方法です。
例えば「word」という単語を検索したい場合、次のように入力します
「~"*word*"」
wordの前後にアスタリスク「*」とダブルクォーテンションマーク「"」で囲み、
一番前にチルダ「~」を付けるというヘンテコなものですが
このような検索の仕方をしないと、
いつまでたっても「Awordtest.txt」は見つけられません。
理由は後で話します。
また、スペースのみ検索したい場合は次のように検索ボックスに入力します。
「名前:~"*? *"」
長いですね。具体的には、「名前」という文字後に半角コロン「:」を入れ、
その後に「~」、「”」、「*」、「?」「 (スペース)」「*」「"」
と入力します。もし入力するのが面倒であれば、上の文字をコピーして下さい。
なぜこのような入力をしないといけないのかは、これまた後で話します。
ファイルの中身から「1234567890」という文字列を検索したい場合は、
次のように検索ボックスに入力します。
「内容:1234567890」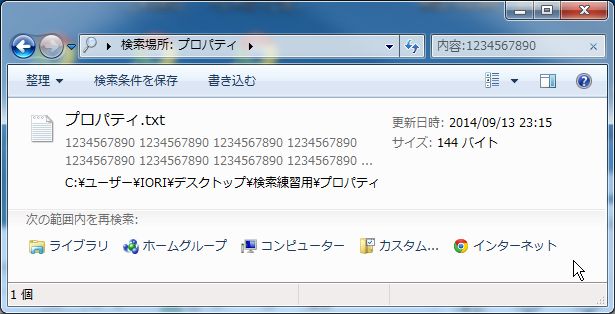
*(表示形式をコンテンツにしています)
その他、検索ボックスで使える例をいくつか下に示します。(検索語が「word」の場合)
| 前方一致 | ~"word*" |
| 後方一致 | ~"*word.txt" |
| 拡張子を無視した後方一致 | ~"*word.*" |
| 部分一致 | ~"*word*" |
| 完全一致 | ~"word" |
| 否定(含まない) | ~!"word" |
ファイル名の先頭の文字で次のように範囲指定することができます。
| 検索語 | |
| 名前:0-9 | 先頭の文字が0~9で始まるもの |
| 名前:A-H | 先頭の文字がA~Hで始まるもの |
| 名前:I-P | 先頭の文字がI~Pで始まるもの |
| 名前:Q-Z | 先頭の文字がQ~Zで始まるもの |
| 名前:かな | 先頭の文字がかなで始まるもの |
| 名前:漢字 | 先頭の文字が漢字で始まるもの |
| 名前:~"*漢字*" | 「漢字」を含むものを検索 |
| 名前:~"*かな*" | 「かな」を含むものを検索 |
次のような範囲指定もできます
| 検索語 | 検出されたファイル | ||
| 名前:(>20 <50) | 20TEXT.txt | 30TEXT.txt | 40TEXT.txt |
| 名前:(>C <F) | C0TEXT.txt | D0TEXT.txt | E0TEXT.txt |
ファイル名以外でも検索できます以下は、更新日時、サイズの検索例です
| 検索語 | 検索対象 |
| 更新日時:今年に入って | 今年に入って更新されたもの |
| 更新日時:<2014 | 2014年までに更新されたもの |
| 更新日時:<2014/8/1 | 2014/8/1までに更新されたもの |
| サイズ:中 | 100KBから1MBまでのもの |
| サイズ:>250KB | 250KB以上のもの |
ここまでが、この話の結論です。これ以降は、なぜこのような検索方法になるのか、
検索の仕組みから説明していくことになります。長くなりますので、
面倒な方は上の例から自分で応用してください。
プロパティの検索
まずは、普通に検索ボックスに入力したときの挙動から始めます。
検索ボックスに「プロパティ」と入力した場合、「プロパティ.txt」という
ファイル名があればそれが検出されます。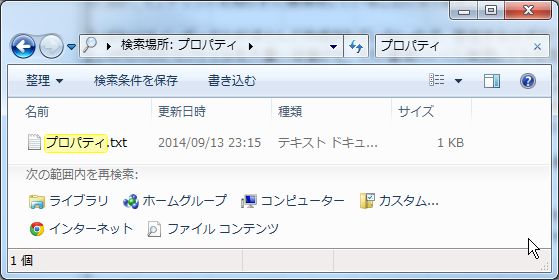
ここまでは、普通の結果だと思います。次に検索ボックスに「144」と入力した場合です。
「144.txt」というファイルが検出されるのは分かりますが、
何故か「プロパティ.txt」も検出されてしまいました。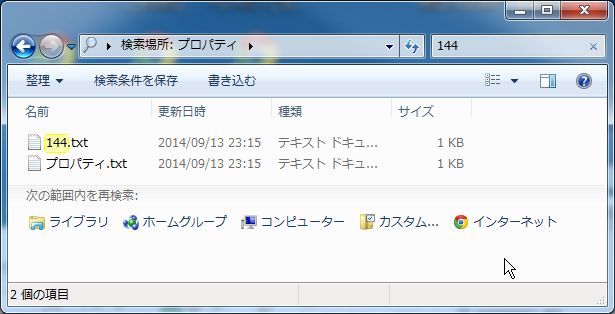
これは謎ですね。原因はプロパティを見れば一目瞭然です。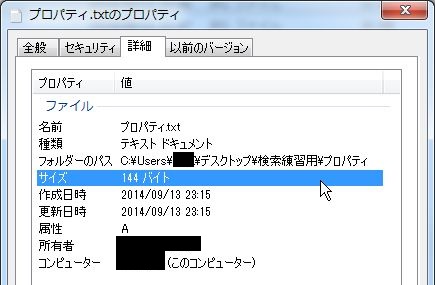
サイズが144バイトとなっています。
つまり、通常検索ボックスに入力した文字列は、
ファイル名だけでなくプロパティの文字列まで検索してしまうのです。
(例外的に属性だけは何故か検索できません)
意図しないファイルが検索に検出されてしまうのは、1つはこれが原因です。
また、インデックスが作成されている場合は、
ファイルの中身まで一緒に検索してしまうのでさらに検索結果が増えてしまいます。
これでは、検索結果が大量にでてしまい、
そこから自分で探していたのでは、検索している意味がありません。
ファイル名だけを探す場合、検索語の前に「名前:」と入力します。
具体的には「名前」の後に半角コロン「:」を入力します。
下図は先ほどの同じフォルダで「名前:144」と入力した例です。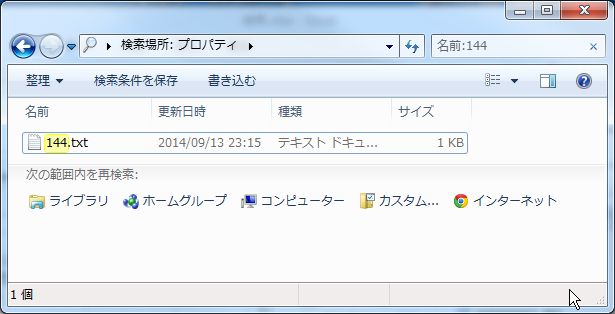
これでようやく、目的のファイルを見つけることができました。
上の図を見ればわかりますが、一番左の列は「名前」と書かれています。
つまりフォルダの表示形式を詳細にしたときに表示される列の名前を使用して
検索することが可能であることを意味します。
試しに、左の列から2番目の「更新日時」で検索してみます。
検索ボックスに「更新日時:2014」と入力します。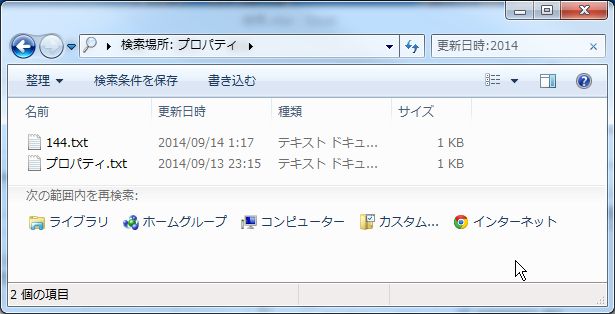
どちらも更新日時が2014年であるため、両方とも検出されます。
さらに日にちを絞る事も可能です。
「更新日時:2014/9/14」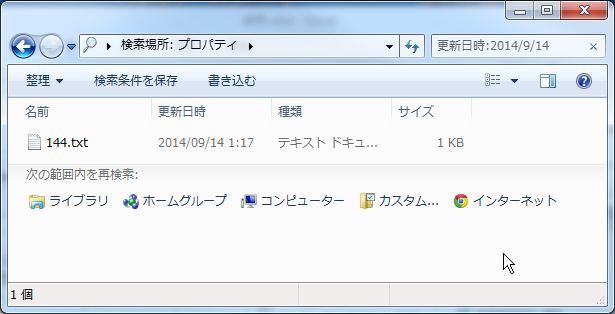
これで、2014年の9月14日に更新されたファイルを検索することができます。
表示形式を詳細にしたときの列の名前は、
他にも「種類」や「サイズ」がありますが、これだけではありません。
列の名前の部分を右クリックし、その他を選択します。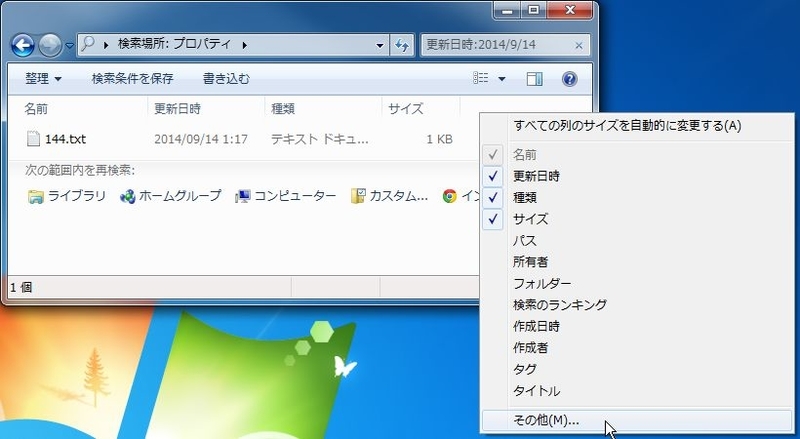
「詳細表示の設定」というダイアログボックスが出てきます。
列に追加できる一覧が出てくるのですが、
あまりにも量が多すぎて、全てに目を通すのは大変です。
そこでIMEをオンにして、わざと全角入力にして、「たかさ」と入力します。
すると左上のほうに、入力した単語が出てきます。
いつもならESCを押して消してしまうところですが、今回はこれを利用します。
スペースで変換し「高さ」になったらエンターを押します。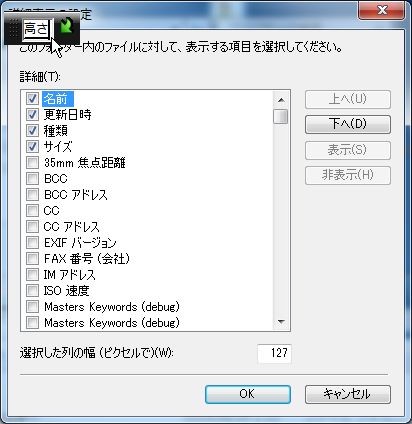
一気に「高さ」の項目までジャンプします。
このテクはフォルダやファイルの選択にも使えます。
「高さ」にチェックを入れてOKを選択します。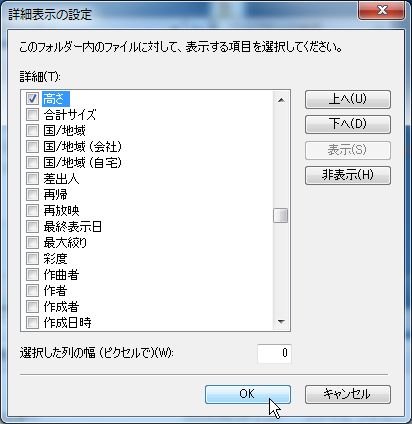
列に「高さ」が加わりました。つまり、高さで検索する事も可能です。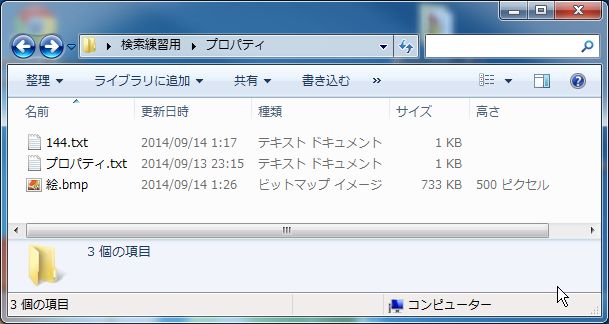
検索ボックスに「高さ:500」と入力します。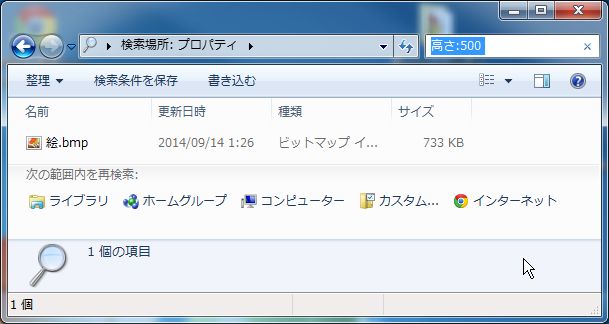
高さ500ピクセルの絵を探すことができました。
別に詳細表示の設定で列を増やさなくても検索できますが、
どのような値があるのか普段から一覧で見る癖をつけていれば
いざというときに探すときの情報が増えて楽です。
また、プロパティの詳細タブからも確認できます。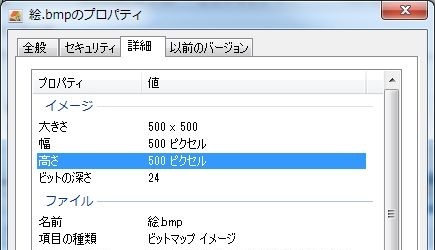
大きさがはっきりとわかっていない場合は範囲指定を行うこともできます。
検索ボックスに「高さ:>100」と入力します。「高さは100以上」という意味です。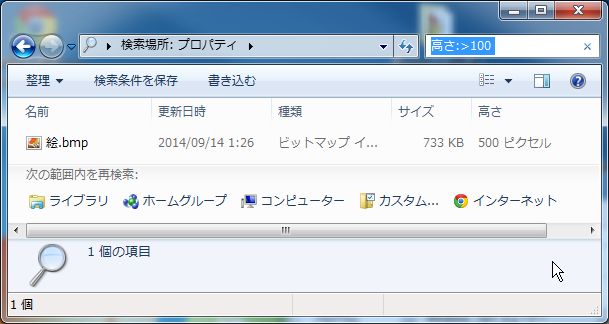
サイズでも指定できますが、このファイルの場合「サイズ:733」と入力しても、
「サイズ:<1000」(サイズは1000未満)と入力しても、検出されません。
なぜなら、このファイルは「733 KB」ではありますが、
正確には「750,054Byte」だからです。
ここでいちいちByteに換算しなくても、単位まで書けば検索できるようになっています。
つまり、検索ボックスには次のように入力します。
「サイズ:<1000KB」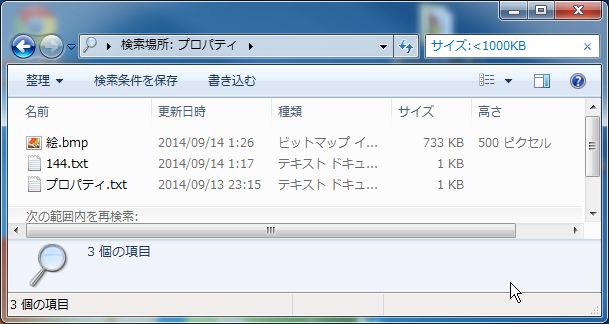
もちろん、数字の後にMBと入力すれば、メガバイトで検索できます。
実はファイル名についても範囲指定ができます。
まずはおおざっぱなやり方から。
フォルダを右クリックして「グループで表示」→「名前」の順に選ぶと、
下のように先頭の文字によって、
「0-9」、「A-H」、「I-P」、「Q-Z」、「かな」、「漢字」というグループに分かれます。
実はこのグループ名はそのまま検索語として使うことができます。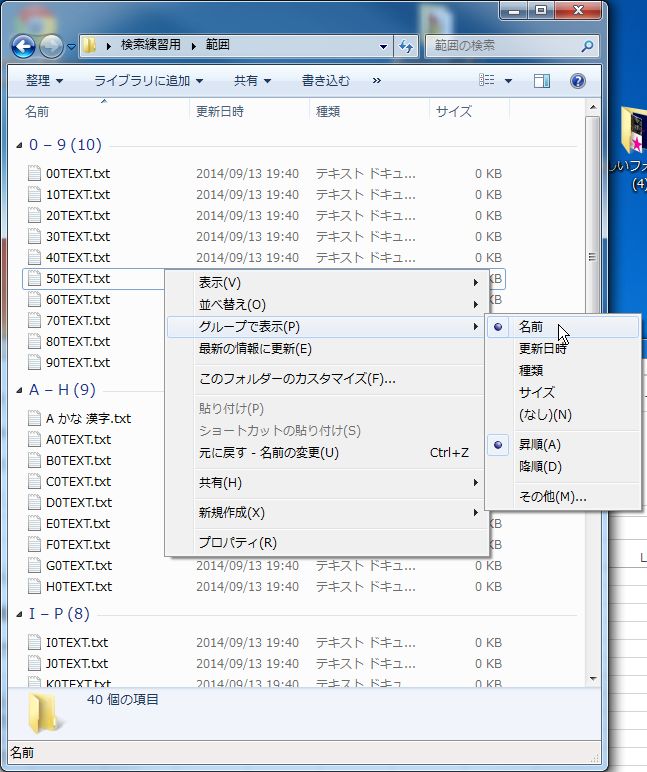
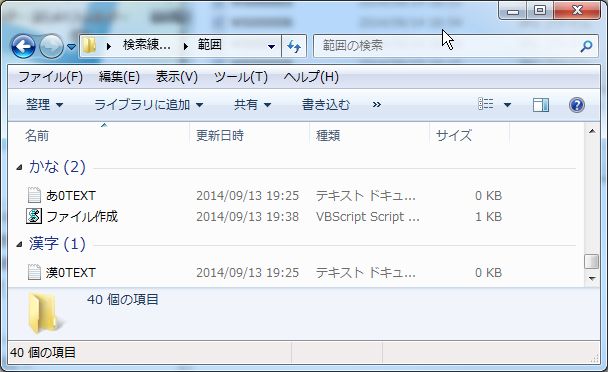
例えば、検索ボックスに、「名前:0-9」と入力します。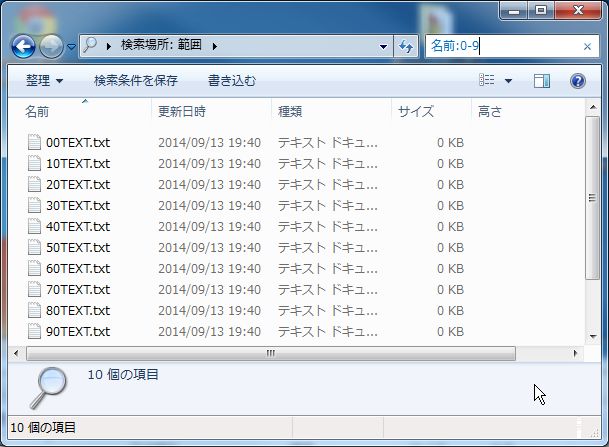
グループ「0-9」が検索されました。
次に検索ボックスに「名前:かな」と入力します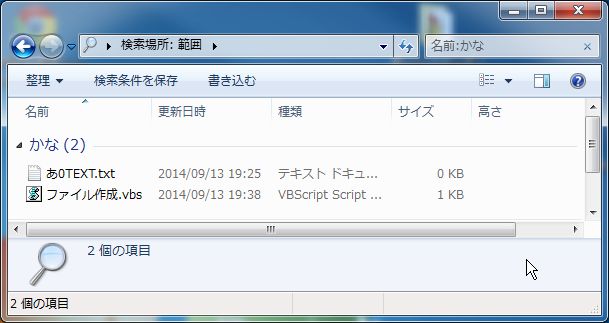
グループ「かな」が検索されます。
まとめると次のようになります。
| 検索語 | |
| 名前:0-9 | 先頭の文字が0~9で始まるもの |
| 名前:A-H | 先頭の文字がA~Hで始まるもの |
| 名前:I-P | 先頭の文字がI~Pで始まるもの |
| 名前:Q-Z | 先頭の文字がQ~Zで始まるもの |
| 名前:かな | 先頭の文字がかなで始まるもの |
| 名前:漢字 | 先頭の文字が漢字で始まるもの |
逆に言えば、ファイル名に「漢字」や、「かな」という文字が含まれるものは、
上記の方法では検索できません。その時は、下記のようにします。
| 名前:~"*漢字*" | 「漢字」を含むものを検索 |
| 名前:~"*かな*" | 「かな」を含むものを検索 |
何故このような入力をするのかは、理由を話すと長くなりますので後で説明します。
説明が前後してしまい申し訳ありません。
また、やはりファイルの名前にも「<」や、「>」を使って範囲指定を行うこともできます。
但し、今度は先頭の文字というわけではなく、先頭から続く数字は全て数字と認識されます。
つまり、「50TEXT.txt」は、「5」ではなく「50」として認識されますので、
0~9の範囲で検索しても検出されないので注意してください。
まとめると次のようになります。
| 検索語 | 検出されたファイル | ||
| 名前:(>20 <50) | 20TEXT.txt | 30TEXT.txt | 40TEXT.txt |
| 名前:(>C <F) | C0TEXT.txt | D0TEXT.txt | E0TEXT.txt |
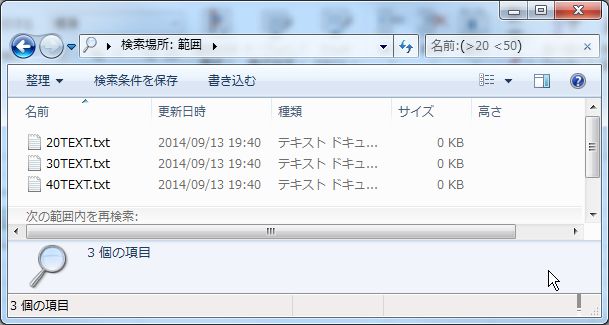
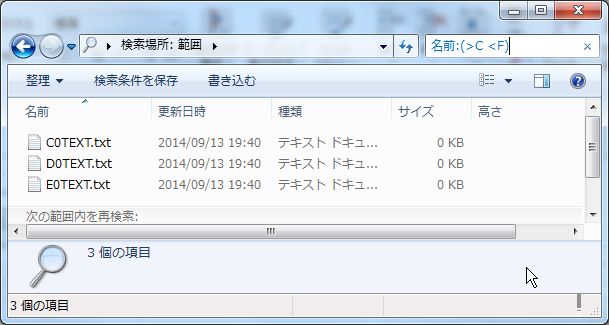
ここで、「>」は以上を表すのに対し、「<」は未満であることに気を付けてください。
「名前:<50」、「名前:<F」としても、「50」や「F」は検出されません。
グループ名による範囲指定や、「>」、「<」による範囲指定は、
名前以外のプロパティにも使用できます 。例えば以下の例です。
| 検索語 | 検索対象 |
| 更新日時:今年に入って | 今年に入って更新されたもの |
| 更新日時:<2014 | 2014年までに更新されたもの |
| 更新日時:<2014/8/1 | 2014/8/1までに更新されたもの |
| サイズ:中 | 100KBから1MBまでのもの |
| サイズ:>250KB | 250KB以上のもの |
更新日時やサイズの場合、「更新日時:」、「サイズ:」と入力した時点で、
グループ名が選択できる新設設計になっています。
プロパティだけでなく、ファイルの中身を検索することができます。(全文検索)
検索ボックスに次のように入力してください。
「内容:123457890」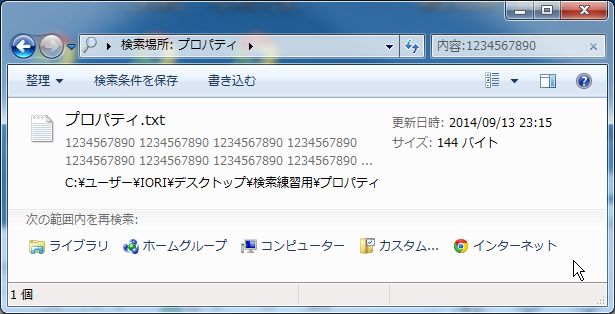
*(表示形式をコンテンツにしています)
追記2021年2月21日
Windows10になってメモ帳のデフォルトがUTF-8になりました。これによりこれから作られる新規のメモ帳はUTF-8が主流になっていくと思います。
ところが、そこに思わぬ落とし穴があります。UTF-8で保存すると「内容:~」で全文検索したときに全角文字が文字化けしてしまい検索できなくなってしまうのです。
その為、テキストファイルの内容を検索したい場合は、メモ帳で保存時に名前を付けて保存で「ANSI」を選択する必要がでてきます。
あるいは、あえて検索ボックスにUTF8になった時の文字化けした文字調べてそれで検索するという方法もあります。
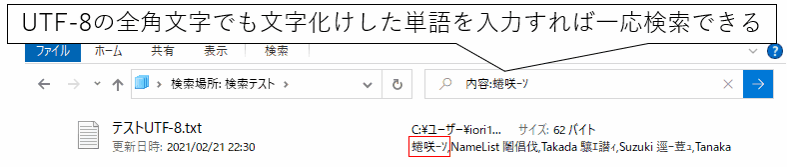
検索ワードを文字化けした状態にする方法は「もじばけらった」というサイトを利用すると簡単にできます
http://lab.kiki-verb.com/mojibakeratta/
また、内容だけでなく、ファイル名やプロパティと同時に検索することが可能です。
インデックスが作成されているファイルは、特に設定はいりませんが、
インデックスが作成されていないファイルも検索したい場合は下記の設定を行ってください。
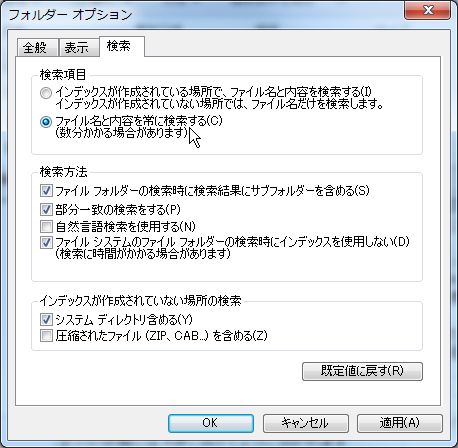
- フォルダの左上にある「整理」を選択します。
- フォルダと検索のオプションを選択し、検索タブを選択します。
- 検索項目の2番目の「ファイル名と内容を常に検索する」にチェックを入れます。
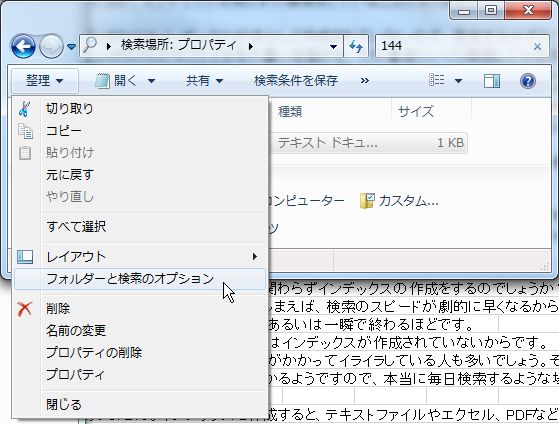
この状態で、検索ボックスに文字列を入力すると、
ファイルの中身とファイル名やプロパティと同時に検索できます。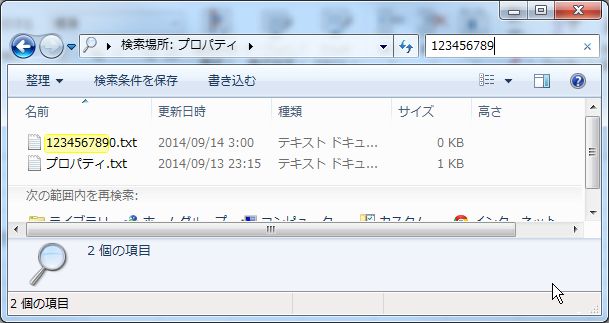
ファイルの中身を検索できる拡張子は、「txt」「xls(x)」「bat」「csv」「doc(x)」等です。
また、インデックスが作成されているファイルについてはPDFも全文検索することが
可能です。ただし、OSが64bitの人は別途「iFilter」のインストールが必要になります。
(32bit用のiFilterはAdobe Readerに含まれています)
64bit用のPDF iFilterは2014年9月現在、下記URLからインストールできます。
http://www.adobe.com/support/downloads/detail.jsp?ftpID=5542
詳しい事は、またインデックス用の記事を後日作成するのでそちらを参照してください。
主に検索できるプロパティは次の通りです。
- 名前:
- 種類:
- 更新日時:
- 作成者:
- タグ:
- サイズ:
- フォルダのパス:
- 所有者:
その他、拡張子によって検索できるものが増えていきます。
Windows7のファイル検索の仕組みについて
ここからは少し込み入った話になっていきますが、
重要な話なので知っておいた方がいいと思います。
windows7はファイル名をいくつかの単語に区切って、
それぞれの単語を前方一致で検索しています。例えば、
「new-cycle」は「new」と「cycle」、
「my cycle」は「my」と「cycle」
といったように分けられます。
しかし、「bicycle」は1つの単語として扱われます。
ここで検索語を「cycle」とすると、
「new-cycle」、「my cycle」は検出されますが、
「bicycle」は検出されません。
これは、「new」と「cycle」は別々の単語として扱われているのに対し、
「bicycle」は1つの単語として扱われている為です。
また、前方一致ですので、「new-cycles」のように後ろに、
複数形の「s」が入っていても、検出されます。
Windowsでは、検索する対象の文字を、次に示す文字でそれぞれの単語に区切っています。
| 区切り文字 | 記号 | 例 | 単語1 | 単語2 |
|
スペース
|
my cycle
|
my
|
cycle
|
|
|
ピリオド
|
.
|
my.cycle
|
my
|
cycle
|
|
ダッシュ(ハイフン)
|
-
|
my-cycle
|
my
|
cycle
|
|
アンダースコア
|
_
|
my_cycle
|
my
|
cycle
|
|
アンパサンド
|
&
|
my&cycle
|
my
|
cycle
|
|
かっこ
|
()[]{}
|
my(cycle)
|
my
|
cycle
|
|
スラッシュ
|
/
|
my/cycle
|
my
|
cycle
|
|
円マーク
|
\
|
my\cycle
|
my
|
cycle
|
*スラッシュと円マークはファイル名には使用できませんが、プロパティには使用できます。
前方一致ではなく、単語単位で完全一致にする場合は、
ダブルクォーテンションマークで囲います。
例えば検索語を「"cycle"」とすると、
「cycle」、「new-cycle」、「my cycle」は検出されますが、
「bicycle」、「cycles」は検出されません。
部分一致や後方一致を使いたい場合は、ワイルドカードを使用します。
ワイルドカードには任意の文字を表す「*」と任意の1文字を表す「?」があります。
「*」は何文字でもよく、たとえ0文字(文字なし)でも構いません。
部分一致の場合、「*cle」などのようにします
また、後方一致の場合は、前に「*」をつけかつダブルクォーテンションマークで囲います。
(例:「"*cle"」、「"*.txt"」)
平仮名や漢字が入っているとかなり複雑になっていきます。
そもそもインターネットで探しても情報がみつかりませんでしたので、
ここは自分で試した結果を載せます。
方法としては、以下のファイル名において、
「名前:""」のダブルクォーテンションマークの間に検索語を入れて確認しました。
| ファイル名 | 単語1 | 単語2 | 単語3 | 単語4 | 単語5 | 単語6 | 単語7 |
| 私のcycle | 私 | の | cycle | ||||
| 私の名前は太郎です | 私 | の | 名前 | は | 太郎 | です | |
| わたしのなまえはたろうです | わたし | の | なまえ | は | た | ろう | です |
| 私野名前は太郎です | 私 | 野 | 名前 | は | 太郎 | です |

*「 ""」の中に最小の単語を入力すると、その部分が黄色くハイライトされる
残念ながら、「たろう」は「た」と「ろう」に分かれてしまいました。
どうやら、漢字にしても平仮名にしても、単語を判定して自動的に区切ってくれるようです。
仕組みは不明ですが、IMEが関係しているのかもしれません。
上記例で通常の検索を行うと、前方一致になりますので、
「私」や「わたし」は検出されますが、
「前」や「ま」「え」「前」、「郎」、「う」は検出されませんでした。
もちろん、「名前」や「太郎」、「な」「なま」、「なまえ」は検出されます。
ここで重量なのは、単語ごとに区切られているからといって、
単語をつなげて検索したら検出されなくなるわけではない、ということです。
つまり、上記の例では、「たろう」という名前が「た」、「ろう」に分かれていますが、
検索語を「たろう」にしても検出されます。
もちろん、「私」と「の」をつなげて「私の」でも検出されます。
一語一句残さずに検索したい場合は、検索語を「*word*」としてください。
上記例で「前」を検索したい場合は「*前*」のように入力すればいいです。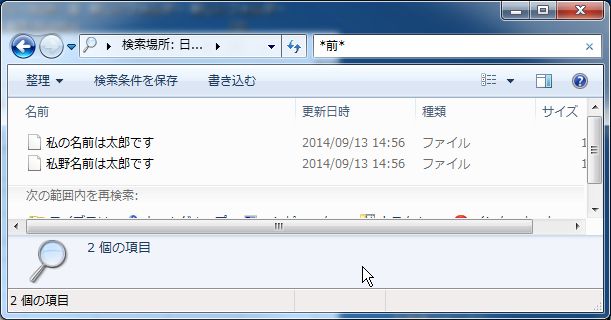
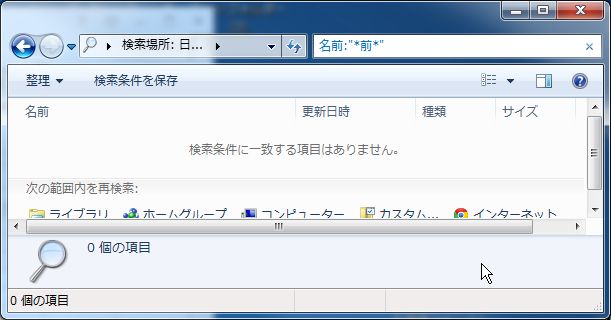
但し、「名前:"*前*"」や「名前:*前*」のように、
「名前:」を付けるとワイルドカードが上手く機能しないことがありますので、
注意してください。
(「名前:」とワイルドカードを組み合わせて、検索する方法は次で紹介します)
さて、今まで通常の検索は前方一致といってきましたが、
それは単語単位の話であって、ファイル単位の話ではないです。
例えば下の例で、検索語を「12」とした場合、どうなるでしょうか?
1234 TEXT.txt
TEXT 1234.txt
答えは「両方とも検索される」です。
なぜなら、どちらも「1234」という単語があるので、前方一致「12」で検出されます。
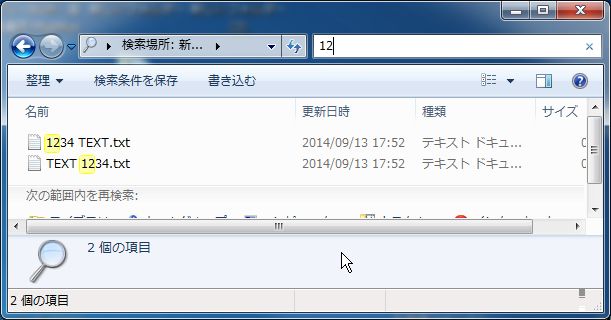
では、ファイル単位で前方一致にさせたい場合どうすればいいでしょうか?
また、ファイル単位で後方一致で検索したい場合や、
または、特殊な記号単体やそれを含む単語を検索したい場合はどうすればいいでしょうか?
また、「名前:」とワイルドカードを組み合わせて上手く検索する方法はないのでしょうか?
これらの検索の方法をまとめて紹介いたします。
検索語を「word」としたとき、それぞれの検索方法は以下のようになります。
| 方法その1 | 方法その2 | |
| 前方一致 | ~<"word" | ~"word*" |
| 後方一致 | ~>"word.txt" | ~"*word.txt" |
| 拡張子を無視した後方一致 | ~="word." | ~"*word.*" |
| 部分一致 | ~="word" | ~"*word*" |
| 完全一致 | ="word" | ~"word" |
| 否定(含まない) | ~!"word" | できない |
ダブルクォーテンションマーク「"」はなくてもいいですが、
スペースなど特殊な文字を含む時に必要になりますので、入れておいたほうが無難です。
方法その1の完全一致以外、「~」(チルダ)がついているのが特徴です。
方法その1はMicrosoftのページにも載っているいわば、「公式」のやり方です。
方法その2は、ソースが不明ですが、なぜかできてしまう裏ワザ的な方法です。
(下記リンク先で紹介されていた方法ですが、ここでも何故できるのかは不明でした)
なぜか検索できない文字でWindowsファイル検索する謎テクニック
通常の場合、方法1と方法2の結果はどちらも同じになります。
しかし、私は方法その2をお勧めします。
理由は、ワイルドカードが使えるからです。
方法その1ではワイルドカードが使えません。
方法その2にある「*」はワイルドカードです。
方法その2について、解説をしていきます。
まず単純に""を付けただけの場合は、単語単位での完全一致を表します。
それに~チルダがついている状態です。
ここでは、「~」チルダは単語単位ではなくファイル単位で検索すると認識してください。
(実際は違うかもしれませんが、この認識で問題ないと思います)
つまり、「~"word"」はチルダによって単語単位からファイル単位に、
ダブルクォーテンションマークによって、ファイル単位の完全一致の検索ができるわけです。
ここで、検索語「word」の前にアスタリスクを付けたらどうなるでしょうか?
アスタリスクは、任意の文字を表すわけですから、
「word」の前にどんな文字が来たとしても、「word」の前に文字がなかったとしても、
検出されることになります。
従って、「~"*word"」は一番後ろに「word」が来る文字が検出されるので、
後方一致と結果が同じになります。
同様に「word」の後に、「*」を付けた場合は、前方一致、
両側に「*」を付けた場合は、部分一致になります。
つまり、方法その2は、「~""」という記述の方式と
ワイルドカードの組み合わせでしかありません。
ややこしいかもしれませんが、理解さえしてしまえば、覚えることがすくないので楽です。
また、ワイルドカードが使えるので、検索の幅ぐっと広がります。
例えば、「最初の文字は12で、途中でEXという文字を含み最後は.txtで終わる」
という検索を行い場合以下のようになります
名前:~"12*EX*.txt"
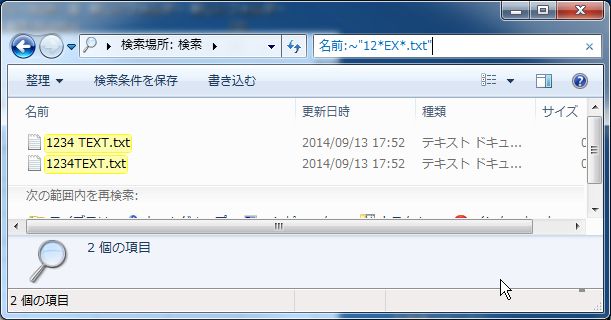
ここでわかるように、「名前:」をつけてもワイルドカードの検索がちゃんとできます。
(単語単位の話では「"*word*"」という表現は、
「名前:」をつけるとまともに機能していませんでした)
また、「☆」や、「-」など特殊な文字も検索できます。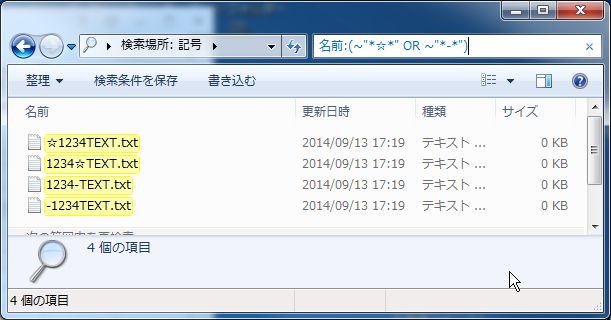
*写真枚数節約のため、ORを入れて2つ同時に検索しています。
スペースのみを検索するときは、「名前:~"*? *"」で、できます。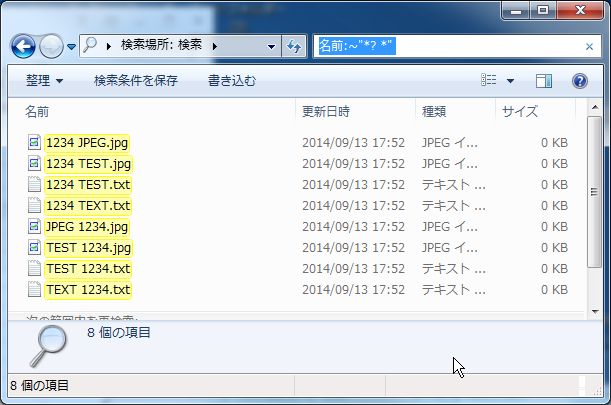
「名前:~"* *"」でも、できるという方がいらっしゃると思いますが、
それはインデックスが作成されているときの話です。
インデックスが作成されていないときは、「名前:~"* *"」では検索できません。
今は、インデックスに関係なく検索できる方法で紹介しています。
蛇足になりますが、「System.FileName:"* *"」としてもスペースのみの検索ができます。
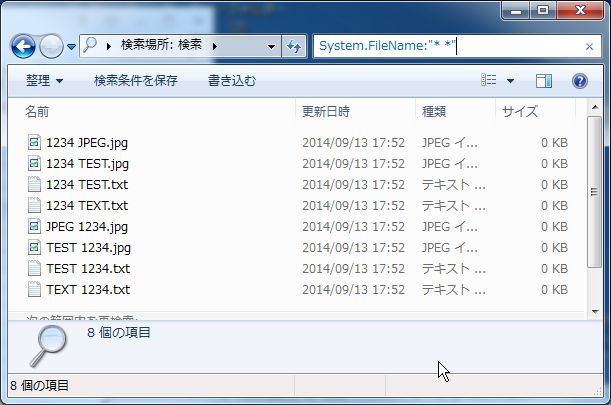
*こちらは、「名前:~"*? *"」と違って黄色のハイライトが消えています。
すなわち、「名前:」と「~""」とワイルドカードを組み合わせて使うと、
ファイル名以外のプロパティを検索することがなく、
ファイル単位での前方一致や、後方一致、部分一致が可能になり、
ワイルドカードを使用することができて、
「-」や「☆」など特殊な記号も検索できて、
スペースのみの検索さえ、可能にしてしまう。
まさに、完璧といっても過言ではないほどの検索方法なのです。
ここで、方法その1と方法その2の違いをまとめておきます。
*全て「名前:」を付けたときの結果をもとにしています。
| 方法その1 | 方法その2 | |
| 基本形式(部分一致) | ~="" | ~"**" |
| ハイライトがかかる部分 | 適切 | 全て |
| 特殊な記号 | 検索できる | 検索できる |
| スペースのみの検索 | できない | 「名前:~"*? *"」で、できる |
| 否定(含まない)の検索 | できる | できない |
| ワイルドカードの使用 | できない | できる |
ハイライトというのは検索された部分が黄色く塗りつぶされた部分のことです。
例えば、検索語を「~="23"」とすると、
ファイル名の「23」の部分が黄色く塗りつぶされます。
しかし、検索語を「~"*23*"」とすると、
ファイル名の全ての部分が黄色く塗りつぶされます。
これは、「*」が任意の全ての文字を表している為、
ファイル名の全ての文字が検索対象に入っているからです。
また、否定(含まない)といった表現はワイルドカードが苦手とする部分です。
検索結果から除外したいファイルがあるのであれば、
方法その1と組み合わせて使いましょう。
今回はここまでです。今まで長かったですが、
ここまでお付き合いくださりありがとうございました。
この記事を書くきっかけになったのは、私自身がWindows7の検索が上手く分からず、
インターネットで探してもいい記事になかなかたどり着けなかった事が発端でした。
特にインデックス関係がややこしく、苦戦しました。
今回はインデックス関係には一切触れませんでしたが、次回、インデックスについての記事を書こうと思います。
この記事書くに至って参考にURLを下に記します。
ファイルを検索するヒント
Windows での検索の高度なヒント
ファイルが見つからない理由
なぜか検索できない文字でWindowsファイル検索する謎テクニック